
77e285ae-b8e3-456a-a0c5-44e16e08bf3bDate generated: May 7, 2026
It’s been a long time, but I’m busy, so I decided to write fewer, more useful posts.
LLMs have targeted the most complex task in systematic reviewing: Data Extraction (Data Abstraction, Data Charting).
RAG
Progress in Retrieval-Augmented Generation (RAG) came with two benefits:
- RAG enabled agentic search tools, such as Undermind and Elicit, that use LLMs to access Knowledge Graphs such as Semantic Scholar, OpenAlex, and Lens.org. RAG + Knowledge Graph = Safety RAG. With Safety RAG, hallucinations are pushed to zero. This means no made-up references, but expect duplicates and the same reference mentioned and cited as two or three different references. I’m not talking about this here.
- LLMs can pay attention to the uploaded/shared document and answer questions or extract data from it, rather than all over the place. This is the feature I focus on here.
Great progress, even exciting, but keep your glasses on!
Factors Affecting the Quality of Data Extraction using LLMs in Systematic Reviews
LLM-based tools have become very good at extracting data, and they keep getting better. Their performance, however we measure it, depends on many factors, just briefly:
Factors related to LLM
- Training data quality
- Training data quantity
- Training data diversity
- Training data contamination
- Model’s size (parameters)
- Architecture of the model
- Number of parameters
- Context window size
- LLM’s version
- LLM’s mode (thinking/reasoning)
- LLM’s personality
- Fine-tuning of the model
- Temperature setting
- Nucleus sampling
- Frequency penalties
- GPU/TPU VRAM and bandwidth
- Quantisation
- Using models specific to medicine/biology
- Customisation of the model
- Memory enabling
- KV caching
- Batching
- Use of RAG
- Use of Model Context Protocol (MCP)
- Use of skills
- Use of multimodal language models
- Choice of evaluation metric
- Use of human-in-the-loop
- …
Factors related to prompting
- Length of prompts
- Iterations/testing (iterative prompting)
- Clarity and precision
- Following a framework
- Few-Shot examples
- Type of prompts (zero-shot, chain-of-thought, hybrid, negative, etc.)
- Use of prompt chaining
- Prompt engineer’s experience
- …
Factors related to the quality of the report
Report/PDF/File can be uploaded or accessed through API
- Length of the file
- Quality of the file
- Format of the file
- Containing image/table/text
- The method used for creating the PDF or file format
- Copyright or technical limitation set on the file (blocking AI or readability)
- Complexity of methods, study design, and data
- …
Factors related to the interface
- Local version (and local hardware)
- API use
- Web UI
- …
Factors related to the requested data
- Data for binary outcome vs continuous outcome
- Numerical vs textual data
- Export format requested
- Source of data: text, table, image, CSV, etc.
- Length of data requested
- Number of data points requested
- …
So, I just tried to give an impression of how complex things can be; however, I’m illiterate in the field of AI, and I cannot expect any systematic review to focus on technical details. What we can do is to check the output and detect the error as Auditors. So, AI Error Vigilancy is the skill to have. Here are some of the errors I have detected, and I hope they help you:
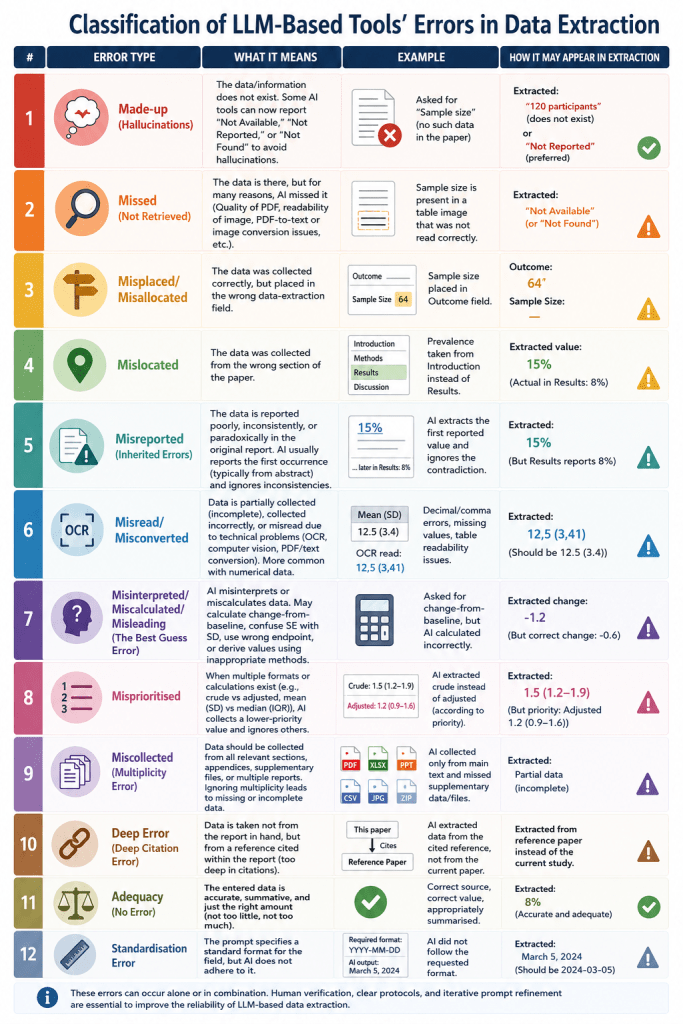
Classification of LLM-Based Tools’ Errors in Data Extraction
However you use LLMs, as a chatbot or embedded within an established systematic review automation tool, you must take into account the possibility of errors. Here, I try to classify the types of errors you should have in mind when checking the data:
Made-up (Hallucinations): The data/information does not exist. Some AI tools can now report “Not Available,” “Not Reported,” or “Not Found” to avoid hallucinations.
Missed: The data is there, but for many reasons, AI missed it (Not Retrieved). The quality of the PDF, the readability of the image, or the PDF-to-text or image conversion process or algorithm may contribute to missing data. AI may report them as “Not Available,” “Not Reported,” or “Not Found” by mistake.
Misplaced/Misallocated: The data was collected correctly, but placed in the wrong data-extraction field.
Mislocated: The data has been collected from the wrong section of the paper. Rather than collecting the prevalence of disease from the Results section, the AI has collected it from the Introduction or Discussion sections.
Misreported (Inherited Errors): The data for the same field has been reported poorly, inconsistently, or, paradoxically, in the original report. AI would usually report the first occurrence of the data, typically from the abstract, and ignore inconsistent or paradoxical reporting of the same data.
Misread/Misconverted: The data is partially collected (incomplete; Selectivity Error), collected incorrectly, or misread due to technical problems, such as readability issues (OCR and Computer Vision) with PDFs or the text converted from the PDF. The risk factors for this error are older files, PDF converted to text, data in tables and figures, or data in image-based tables/figures. This error occurs more with numerical data.
Misinterpreted/Miscalculated/Misleading (The Best Guess Error): AI misinterpreted the data. It is likely that when we ask for change-from-baseline data for an outcome, and it is not readily available, AI may miscalculate it or interpret the wrong data (Endpoint or Baseline) as the correct one. Interpreting SE as SD is also possible. Such calculations may need a protocol/method to follow, and AI may or may not have it. For example, calculating the mean and SD from the median and IQR may follow different methods depending on the sample size. Another example is taking the affiliation country as the country of study.
Misprioritised: If there are multiple formats/calculations for the same data (crude vs adjusted, mean and standard deviation (SD) vs median and IQR), AI may collect the data that is not a priority and ignore the other occurrences.
Miscollected (Multiplicity Error): The risk-of-bias data should be collected from all sections of the paper, not just the methods section. Other data may be collected from the paper, its appendices (in multiple formats, e.g., XLSX, PPT, JPG, CSV, ZIP, etc.), or multiple reports (papers/PDFs) of the same study. Ignoring multiplicity can miss data or lead to incomplete data or risk-of-bias assessment.
Deep Error: If the collected data is not from the report in hand, but from a reference cited within the report. I called it Deep Error. It’s a comeback to those tools that claim to have Deep Search and Deep Research capabilities! Sometimes, they go too deep. I’m looking for a better name for this error: Source Hierarchy Error, Secondary Source Error, Indirect Citation Error, or Deep Citation Error.
Inadequacy Error: If the entered data is accurate, summative, and information (not too little, not too much, but just enough).
Standardisation Error: While the prompt may specify a standard format for the field, the AI may not adhere to it.
Conclusion
Does AI Save or Take Time?
I’m not being cynical; most research reports an accuracy of 50% to 90%, so AI is helpful. But sometimes, finding those inaccuracies can take even more time than data extraction itself; spot the irony! If you deal with 10 studies, deal with it, don’t be lazy! After you finish, ask AI to do it, check your work against AI’s and publish it as a blog or a paper.
Explainability or Seeing Is Believing (SIB)
Advice: If you have to use LLMs, either use tools that let you check each piece of collected data by clicking it and seeing its location in the report, or open the report and double-check it. While such action cannot mitigate all risk or resolve all errors, it can help reviewers realise their responsibility and keep them alert to errors.
Please share your thoughts and let me improve this post; I will acknowledge any contributions.
If you liked this blog post, please subscribe to our newsletter.
Cite as: Shokraneh, Farhad. Classification of LLM Errors in Data Extraction for Systematic Reviews and Factors Affecting the LLM-Based Tool’s Performance. Systematic Review Consultants LTD. 7 May 2026; [Revised 27 July 2026]. Available from: https://systematicreview.info/2026/05/07/
